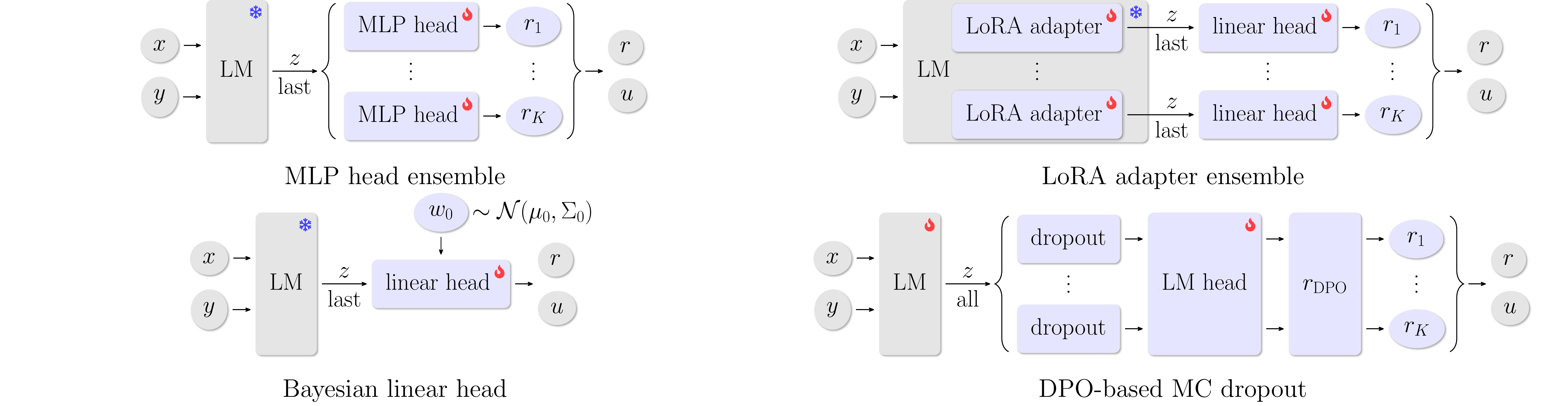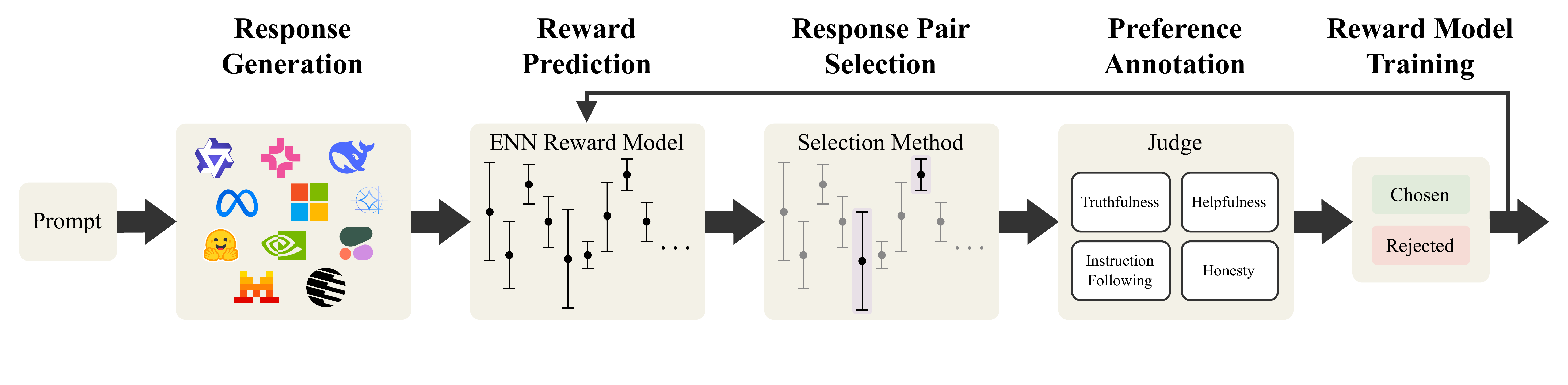
Active Learning for Preference Data Generation
ActiveUltraFeedback: Efficient Preference Data Generation using Active Learning
ActiveUltraFeedback is a modular pipeline for collecting high-quality preference data more efficiently. By using uncertainty-aware response selection, it identifies informative response pairs for annotation and can achieve strong downstream performance with substantially fewer labels than static baselines.